
Los modelos de razonamiento como DeepSeek-R1 no simplemente “piensan durante más tiempo”. Según un nuevo estudio, simulan internamente una especie de debate entre distintas perspectivas que se cuestionan y corrigen mutuamente.
Investigadores de Google, la Universidad de Chicago y el Santa Fe Institute analizaron por qué modelos de razonamiento como DeepSeek-R1 y QwQ-32B rinden significativamente mejor en tareas complejas que los modelos lingüísticos convencionales. Descubrieron que estos modelos generan una “sociedad del pensamiento” dentro de sus trazas de razonamiento: múltiples voces simuladas con distintas personalidades y áreas de especialización que dialogan entre sí.
Debates internos en los modelos de razonamiento
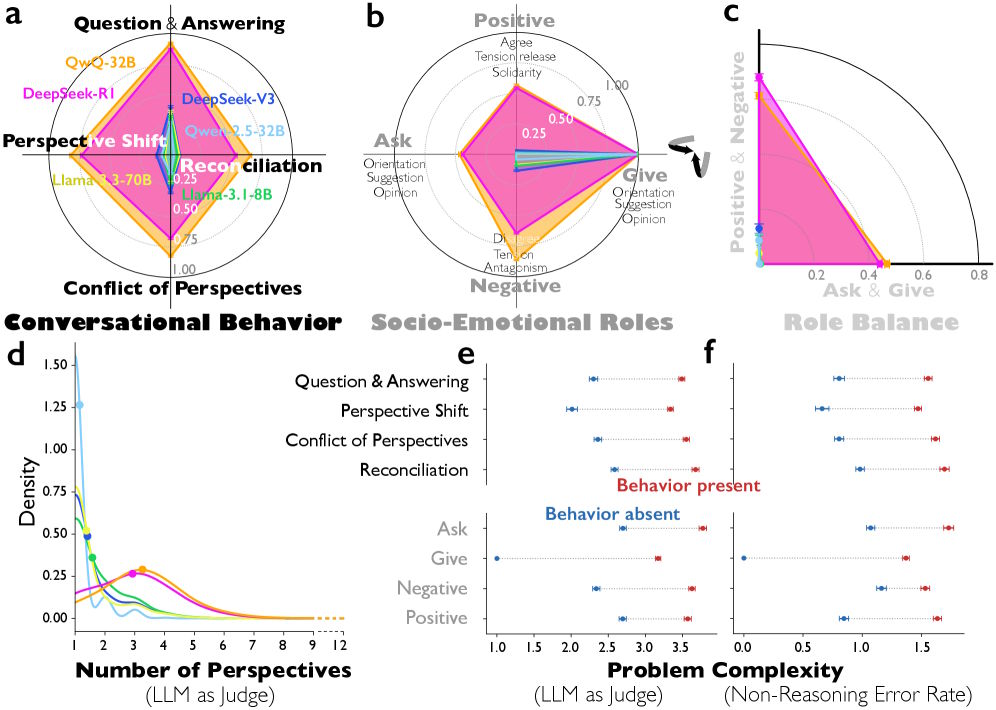
El análisis de más de 8.000 problemas de razonamiento reveló diferencias claras entre los modelos de razonamiento y los modelos estándar ajustados por instrucciones. En comparación con DeepSeek-V3, DeepSeek-R1 muestra muchas más secuencias de pregunta-respuesta y cambios de perspectiva más frecuentes. QwQ-32B también presenta muchos más conflictos explícitos entre distintos puntos de vista que el comparable Qwen-2.5-32B.
Los investigadores identificaron estos patrones mediante un enfoque de LLM-as-judge, en el que Gemini 2.5 Pro clasificó las trazas de razonamiento. La concordancia con evaluadores humanos fue considerable.
Un transcript ficticio de chat ilustra los pasos cognitivos de una IA, complementado con diagramas de red que representan distintos perfiles de personalidad de los agentes simulados.
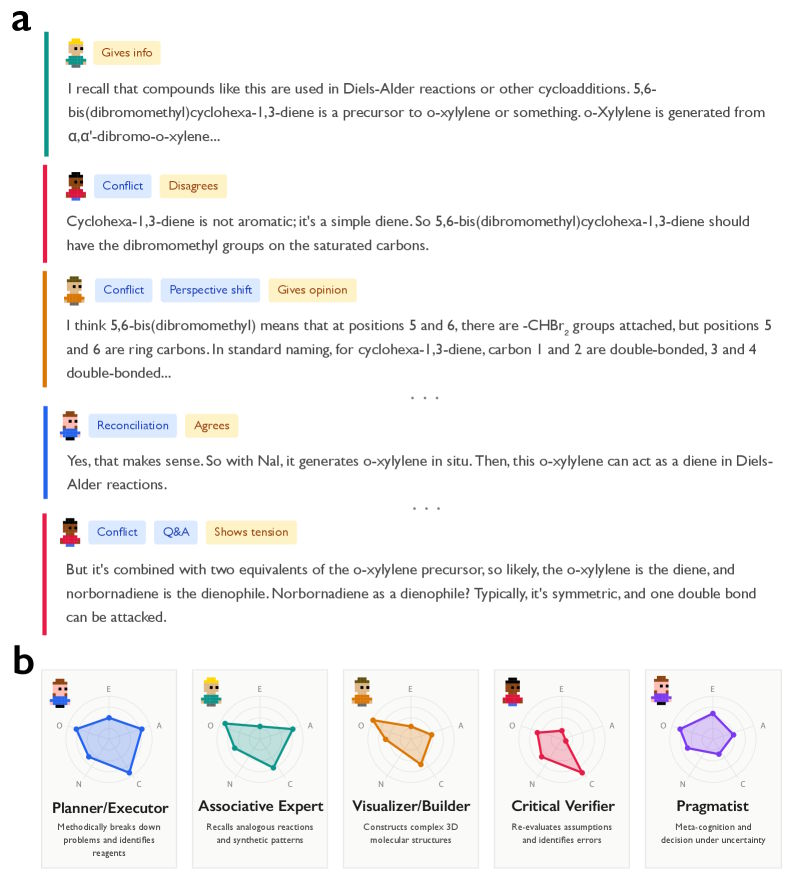
Un ejemplo del estudio destaca la diferencia: en un problema complejo de química sobre una síntesis de Diels–Alder en múltiples etapas, DeepSeek-R1 mostró cambios de perspectiva y conflictos internos. El modelo escribió, por ejemplo: «Pero aquí es ciclohexa-1,3-dieno, no benceno», cuestionando sus propias suposiciones. DeepSeek-V3, en cambio, produjo una cadena lineal de opiniones sin autocorrección y llegó a un resultado incorrecto.
Diferentes personalidades en el proceso de razonamiento
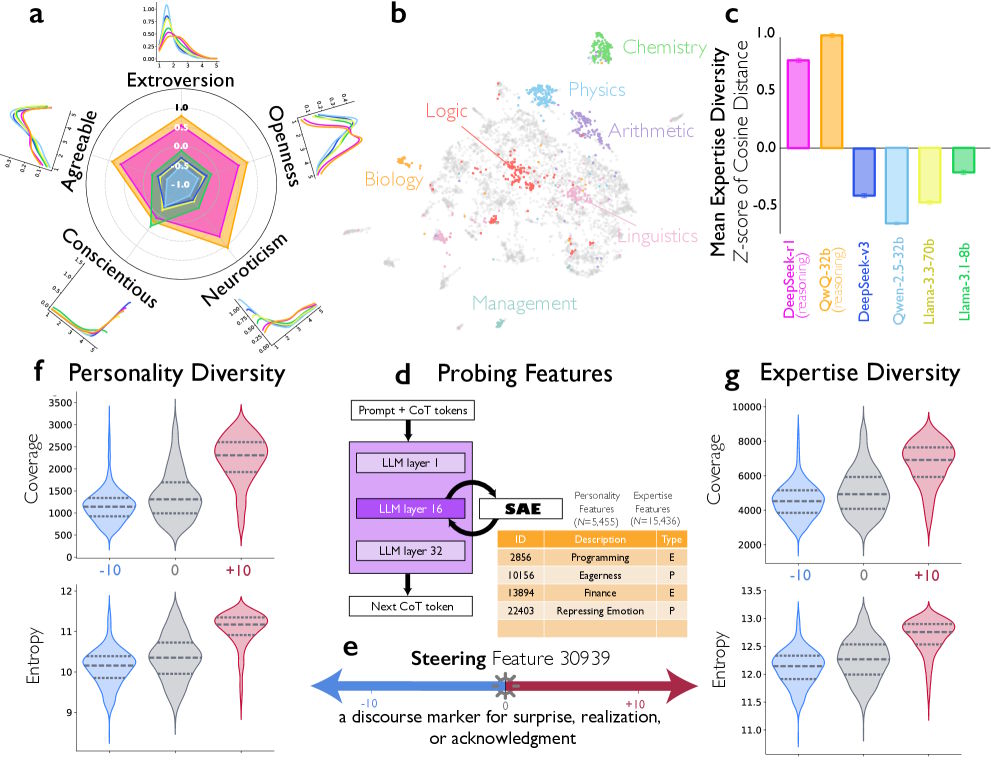
Los investigadores fueron un paso más allá y caracterizaron las perspectivas implícitas dentro de las trazas de razonamiento. DeepSeek-R1 y QwQ-32B mostraron una diversidad de personalidad significativamente mayor que los modelos ajustados por instrucciones, medida en las cinco dimensiones de los Big Five: extraversión, amabilidad, responsabilidad, neuroticismo y apertura.
Seis diagramas que analizan el razonamiento de la IA muestran gráficos radiales de roles y comportamientos, así como gráficos de la complejidad de los problemas.
Curiosamente, la diversidad en responsabilidad fue menor: todas las voces simuladas parecían disciplinadas y diligentes. Según los autores, esto coincide con hallazgos de la investigación sobre equipos, que sugieren que la variabilidad en rasgos orientados a lo social, como la extraversión y el neuroticismo, mejora el rendimiento del equipo, mientras que la variabilidad en rasgos orientados a la tarea, como la responsabilidad, puede ser perjudicial.
En una tarea de escritura creativa, el LLM-as-judge identificó siete perspectivas distintas en la traza de razonamiento de DeepSeek-R1, entre ellas un «generador creativo de ideas» con alta apertura y un «verificador de fidelidad semántica» con baja amabilidad, que planteó objeciones como: «Pero eso añade ‘deep-seated’, que no estaba en el original».
La orientación de características duplica la precisión
Para comprobar si estos patrones conversacionales causan realmente un mejor razonamiento, los investigadores utilizaron una técnica de interpretabilidad mecanicista que revela qué características internas activa un modelo.
Identificaron una característica en DeepSeek-R1-Llama-8B asociada a señales conversacionales típicas —como sorpresa, comprensión o confirmación— comunes durante los cambios de interlocutor.
Cinco diagramas muestran cómo la activación de características conversacionales humanas mejora el razonamiento lógico de una IA.
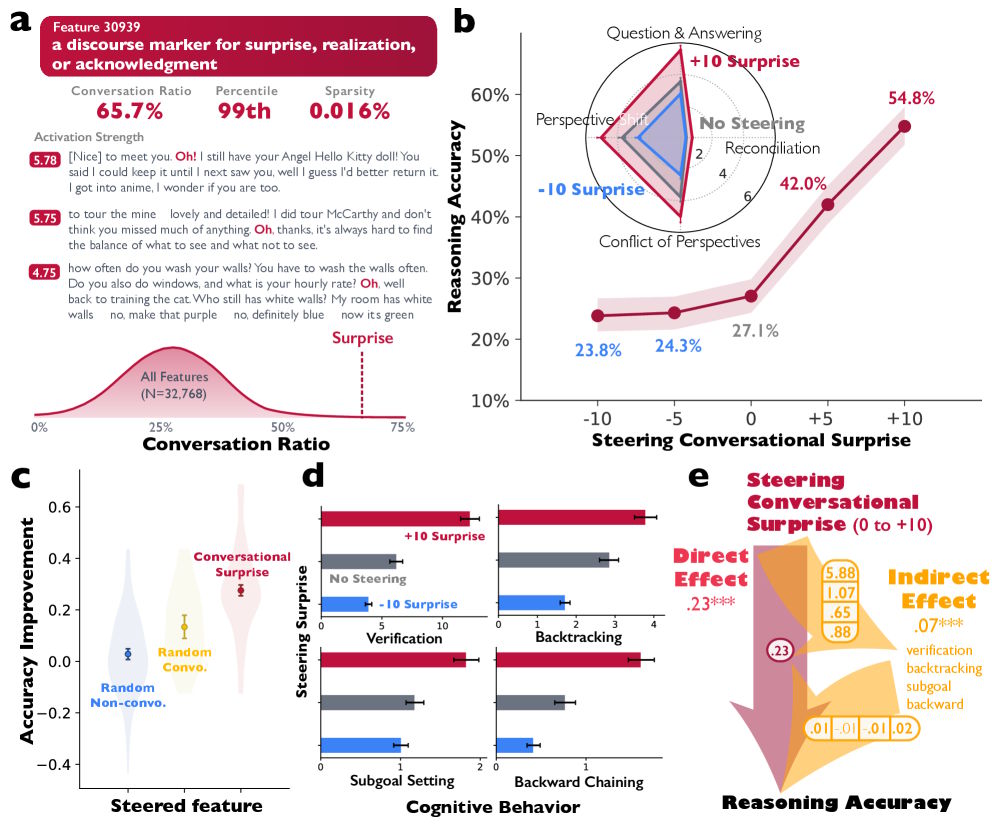
Cuando los investigadores amplificaron artificialmente esta característica durante la generación de texto, la precisión en una tarea matemática se duplicó del 27,1% al 54,8%. Al mismo tiempo, los modelos se comportaron de forma más dialógica: verificaron resultados intermedios con mayor frecuencia y corrigieron errores por sí mismos.
El razonamiento social emerge espontáneamente mediante aprendizaje por refuerzo
El equipo también realizó experimentos controlados de aprendizaje por refuerzo. Los modelos base desarrollaron espontáneamente comportamientos conversacionales cuando fueron recompensados por la precisión, sin ningún entrenamiento explícito en estructuras de diálogo.
El efecto fue aún más fuerte en modelos previamente entrenados con trazas de razonamiento de tipo dialogado: alcanzaron una alta precisión más rápido que los modelos entrenados con trazas lineales y monológicas. Por ejemplo, los modelos Qwen-2.5-3B entrenados con razonamiento dialogado alcanzaron alrededor del 38% de precisión tras 40 pasos de entrenamiento, mientras que los modelos entrenados de forma monológica se estancaron en el 28%.
Estas estructuras de razonamiento dialogadas también se transfirieron a otras tareas. Los modelos entrenados en debates simulados para problemas matemáticos aprendieron más rápido incluso al identificar desinformación política.
Paralelismos con la inteligencia colectiva
Los autores trazan paralelismos con la investigación sobre la inteligencia colectiva en grupos humanos. La teoría del «Enigma de la razón» de Mercier y Sperber sostiene que el razonamiento humano evolucionó principalmente como un proceso social. El concepto del «yo dialógico» de Bajtín describe de forma similar el pensamiento como una conversación internalizada entre distintas perspectivas.
El estudio sugiere que los modelos de razonamiento forman un análogo computacional de esta inteligencia colectiva: la diversidad mejora la resolución de problemas, siempre que esté estructurada de forma sistemática.
Los investigadores subrayan que no afirman que las trazas de razonamiento representen literalmente un discurso entre grupos humanos simulados o una mente que simula interacción multiagente. Sin embargo, las similitudes con los hallazgos sobre equipos humanos eficaces sugieren que los principios del trabajo en grupo exitoso podrían ofrecer orientaciones valiosas para el desarrollo del razonamiento en modelos de lenguaje.
En el verano de 2025, investigadores de Apple plantearon dudas fundamentales sobre las capacidades de «pensamiento» de los modelos de razonamiento. Su estudio mostró que modelos como DeepSeek-R1 fallan a medida que aumenta la complejidad del problema y, de forma paradójica, piensan menos. El equipo de Apple interpretó esto como un límite fundamental de escalado.



 ES
ES  EN
EN